Как построить поисковую систему с максимально релевантными результатами
О клиенте
Клиент — международная IT-компания, разрабатывающая программное обеспечения для создания технической документации.
Задача
Информации на сайте сервиса стало так много, что потребовалась поисковая система. Клиент предоставил подробную спецификацию для разработчиков, в которой учёл значительную часть требований к форматам, работе и результатам поиска и к Drupal CMS.
Решение
Часто для настройки поиска на Drupal-сайте используется модуль Search API. Этот модуль служит прослойкой между Drupal и разными поисковыми движками, в том числе Apache Solr, который команда ADCI Solutions использует на проектах чаще всего. В Search API много настроек как для сайта на Drupal, так и для Apache Solr, который учитывает, что важно хранить, чтобы информация находилась лучше.
В таких случаях работа Drupal-разработчиков сводится к установке модуля, настройке сервера и стандартных параметров. Казалось, что на этом проекте работа пойдёт точно так же. Но только на первый взгляд.
Сервер
Клиент дал нам доступ к dev, stage и prod-серверам. Чтобы настроить Apache Solr на всех трёх серверах с нуля, наш тимлид попробовал себя в роли DevOps-инженера. Кроме того, нужно было подобрать правильную версию Solr: седьмая вызывала больше доверия, но восьмая максимально поддерживается Drupal — на ней в итоге и остановились.
Новая для нас задача и её изначальные условия не позволили нам решить её быстро, поэтому работа затянулась на пару десятков часов. Теперь у нас есть необходимые навыки, которые в подобной же ситуации на следующих проектах позволят потратить на задачу 2-3 часа. Но затраты времени, так или иначе, зависят от обстоятельств.
Поиск
Как сказано выше, спецификация очень подробно объясняла, что и как должно работать. Но несколько моментов всё же было упущено.
Поиск состоит из двух глобальных частей: строка поиска в хэдере со значком лупы и сама страница с результатами поиска, которой передаётся запрос, оставленный в поисковой строке.

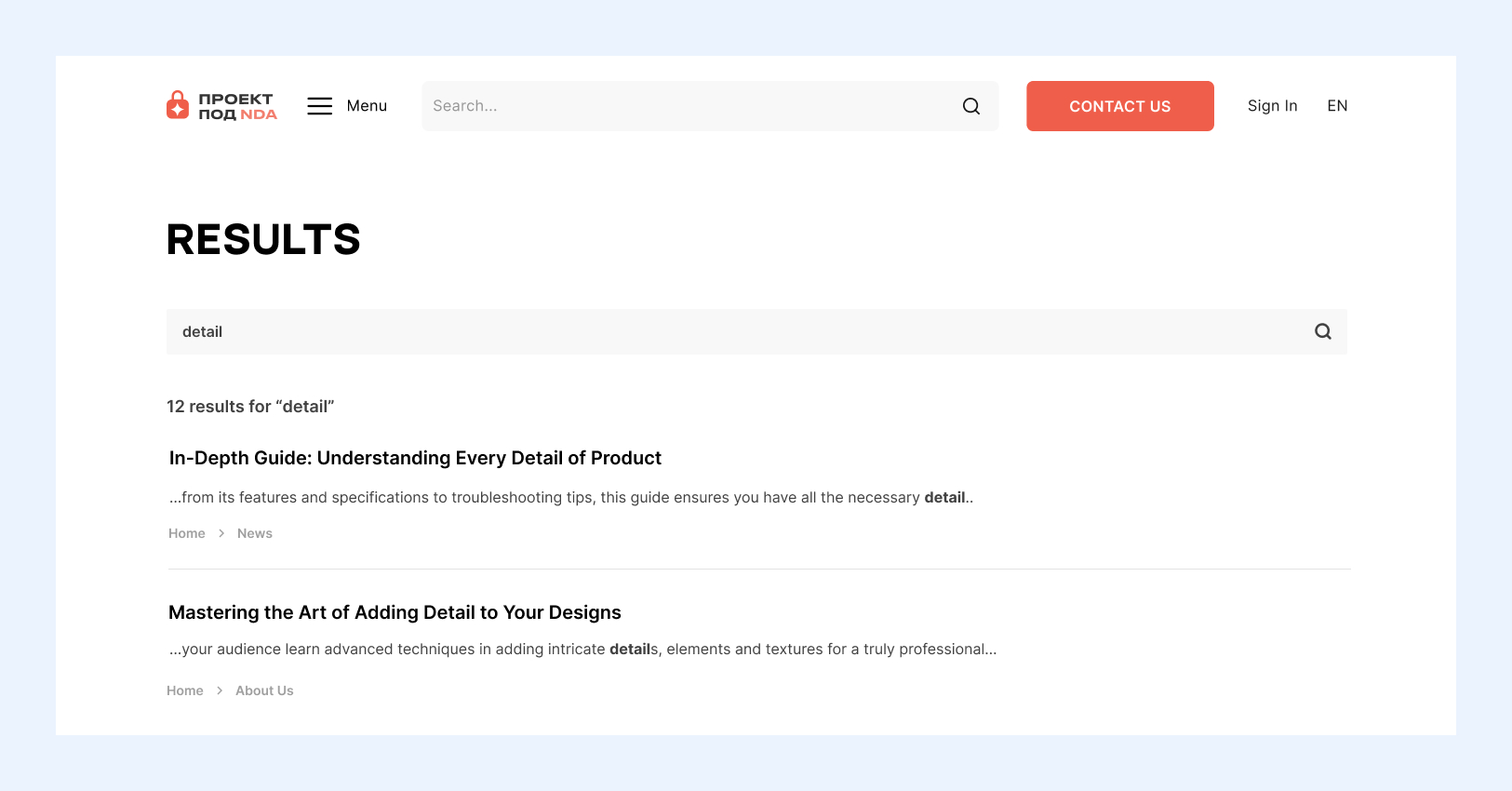
Также есть категории поиска для фильтрации общей поисковой выдачи.
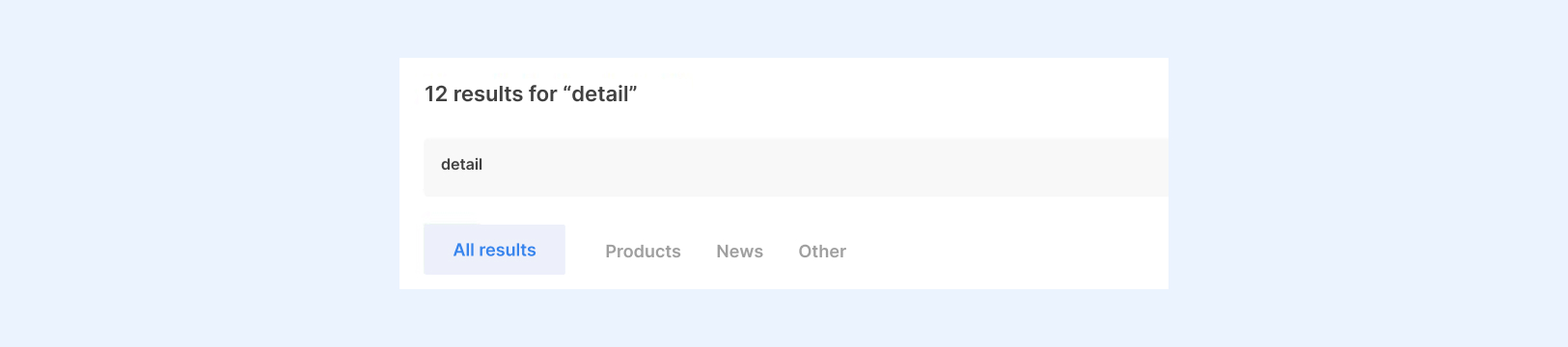
Результат поиска — это заголовок, summary с искомым словом и его вариациями, и хлебные крошки.
У сайта есть несколько языковых версий. Содержание поисковой выдачи зависит от того, какую версию выбрал пользователь: поиск по немецким словам в английской версии ничего не даст, как и наоборот.
Хлебные крошки
Хлебные крошки стали проблемой номер один. В дизайне они были очень длинные и могли выходить за пределы страницы. У клиента возникла идея: закрывать троеточием часть строки, которая не влезает на страницу. Но каждая часть хлебных крошек — кликабельная, и если скрыть ту часть, которая не влезла, пользователь не поймёт, где он находится и не сможет перейти в следующий раздел. Мы успешно объяснили это клиенту и с помощью CSS настроили перенос строк.
Вывод искомых слов
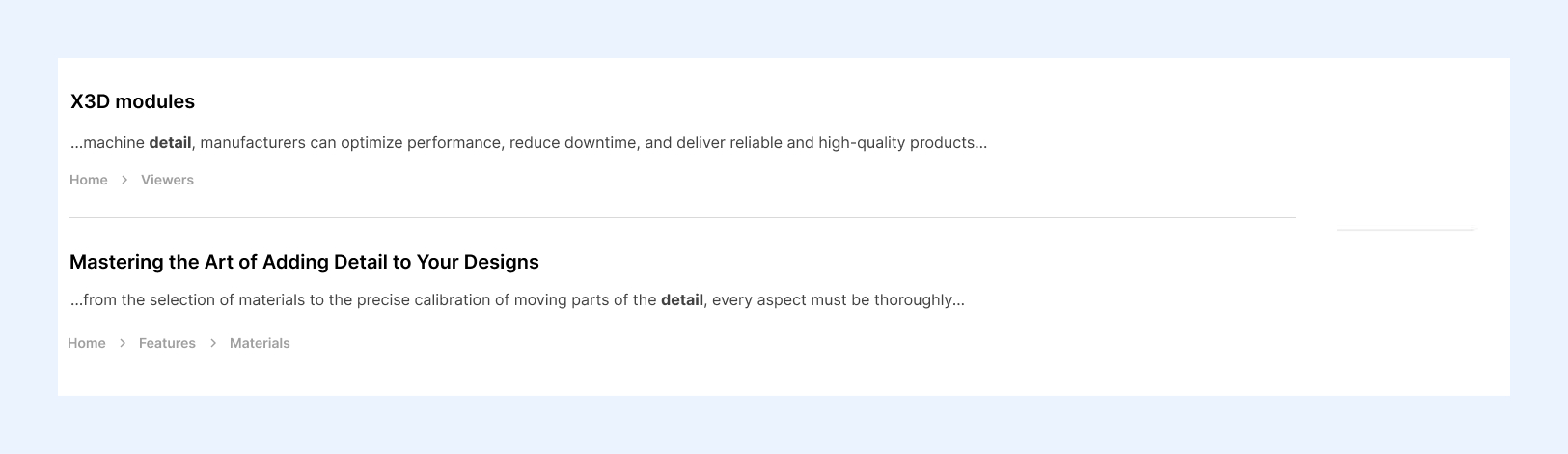
Согласно ТЗ, часть текста из найденных материалов, которое мы называем summary, должна была всегда включать слова из строки поиска и выводить их жирным начертанием на фоне остального текста. Изначально так не работало. Summary формируется работой Search API, который проходит страницу сверху вниз и вытягивает строчки текста с запрошенным словом. Иногда в summary попадала первая часть предложения, в котором слово есть, но оно не влезло в эту часть. В Search API за это отвечает PHP-файл highlight processor, но мы написали кастомный модуль, скопировали в него этот файл и настроили механизм подсвечивания так, как было нужно нам.
Сортировка результатов поиска
Результаты поиска мы пытались сортировать с точки зрения релевантности. В верхние позиции попадали заголовки, содержащие запрошенное слово, следом идут результаты с этим словом и образованными от него словами, но уже в самом материале. Для такой сортировки мы использовали плагин Ngram для Solr. Он способен разглядеть запрошенное слово в производных от него, что делает результаты поиска глубже и полнее.
С помощью процедуры Boosting results каждому результату поиска присваивается своё место в выдаче. Суть процедуры — в перемножении показателя boost factor, который задаётся разработчиком, и показателя релевантности контента relevance score («оценка релевантности»), который задаётся в Solr. Чем больше значение boost factor, тем выше результат поиска будет в выдаче.
Итоги
За исключением не влияющих на поисковую выдачу проблем в работе Solr наша команда выполнила свою работу полностью.


